|
Donghwa Kim I'm a software engineer at Samsung Research. I got my M.S degree from Graduate School of Data Science (GSDS) at Seoul National University. I was advised by Professor Joonseok Lee, as a member of Visual Information Processing Lab (VIPLab). Prior to my graduate studies, I majored in astronomy and minored in physics. |

|
ResearchI'm interested in computer vision, multimodal representation learning, foundation models. Most of my research is about analyzing existing mulimodal model and improving its application capabilities. |
|
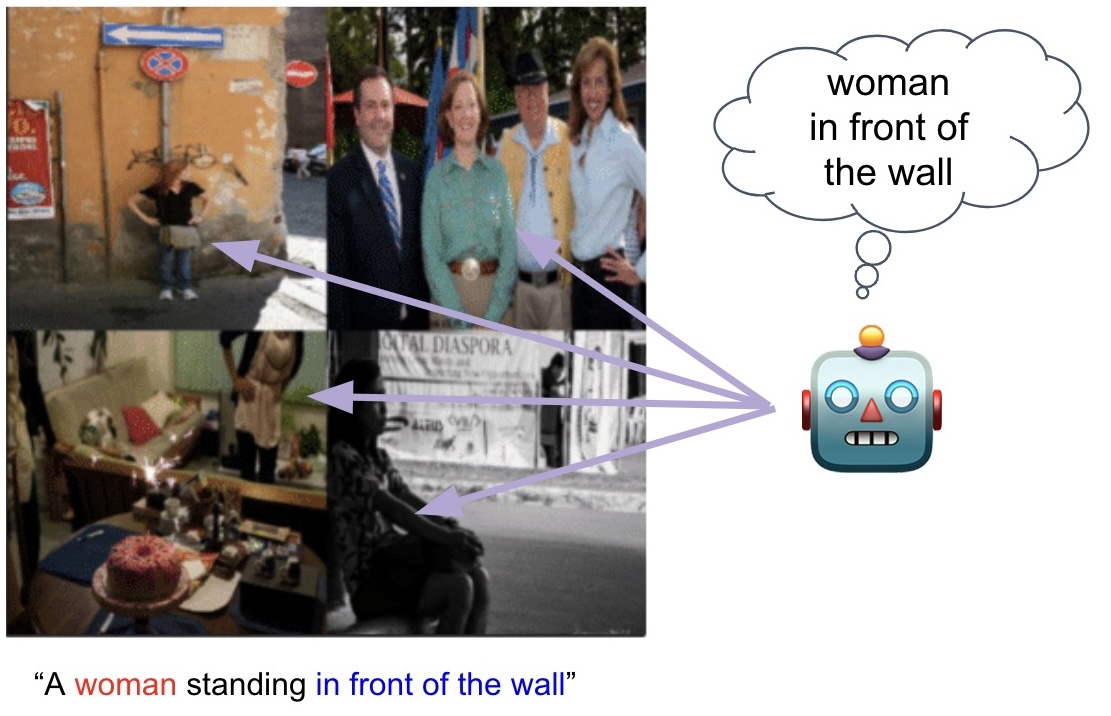
Finding NeMo: Negative-mined Mosaic Augmentation for Referring Image Segmentation
Seongsu Ha*, Chaeyun Kim*, Donghwa Kim*, Junho Lee, Sangho Lee, ECCV, 2024 project page / arXiv We propose a simple but powerful data augmentation method which augments a training image into a mosaic with three other negative images carefully curated by a pretrained multimodal alignment model, e.g., CLIP, to make the sample more challenging. |
|
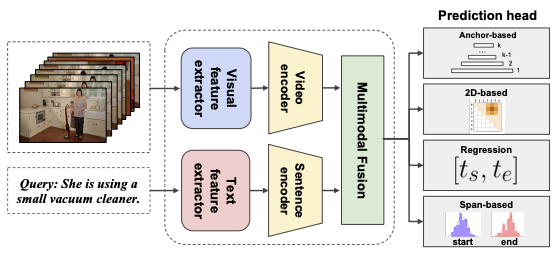
Towards a Complete Benchmark on Video Moment Localization
Jinyeong Chae*, Donghwa Kim*, Kwanseok Kim, Doyeon Lee, Sangho Lee, Seongsu Ha, Jonghwan Mun, Wooyoung Kang, Byungseok Roh, Joonseok Lee, AISTATS, 2024 PMLR We conduct an extensive benchmark study to measure the performance of representative methods on widely used 7 datasets, while posing additional research questions and empirically verify them. |
Work Experience |
|
Oct. 2024 – Present Seoul, Korea |
Samsung Electronics · Software Engineer Samsung Research → AX Team (Management Diagnosis Office) DoXA — Document Extraction and Analysis (Internal Service, 2025.01–2025.12)
Ehcro — Multi-Agent Orchestration Engine (Internal Service, 2026.01–2026.05)
Rosetta — Internal Translation Agent Service (2026.06–Present)
|
|
Sep. 2021 – Dec. 2021 Seoul, Korea |
SETsystem · AI Research Intern
|
|
This page is a fork of Jon Barron's. Thank you for sharing :) |